
I’m doing my honour’s thesis! The topic here is about Just-in-Time query compilation in Relational Database engines. Step one here is to collect information about the current databases that do this, how they function and whether they’re actually good. This page is a quick summary about the options around and how they work.
Most of the databases are from dbdb io
Relevant databases
Open Source Databases
LLVM-backed
Lingo Db
Website | Code | Research papers one two | Benchmarking Tools
Transclude of benchmark_output.txt
Their main ideas seem to be about making sub operators (scan, materialize, scatter, gather, map, fold, and loop) first-class entites and they use MLIR to support their compiler. The impressive thing is that it’s very few lines of code - only about 2.5K - and they manage to get their query compiler quite reasonably fast. This means it’s a good starting point for understanding the topic of my thesis, since it’s mostly about the JIT compiler. It supports enough SQL operations to run TPC-H benchmarks
Impala
This also uses LLVM, and it’s quite old. The last stable release was only two years ago, so it might be quite an interesting, older sample of a JIT compiler.
Apache Kudu
Another interesting LLVM JIT one. I suspect the compiler is going to be very similar to Impala
NoisePage
Seems to be archived on github, but the description seems worth mentioning. It compiles their programming language into bytecode and then those can be handled with LLVM.
OpenMLDB
Yet another LLVM-able JIT compiler. Seems to be built for machine learning applications.
SingleStore
https://dbdb.io/db/singlestore
Seems to be yet another LLVM powered query compiler. However, it has more steps before feeding it into LLVM
Postgresql
https://www.postgresql.org/docs/current/jit.html
Seems they have some level of JIT support, but I’m not sure how deep it goes
JVM-backed
Derby
Derby parses the prepared statement using Javacc and generates the Java binary code directly. JIT complier is supported, so that after several executions, JIT compiler will compile it to native code for performance improvement.
Neo4j
The world’s leading graphs database. Seems worth checking out.
OrientDB
Yet another database that’s supported by the JVM compiler in its query optimizations
PrestoDB
This one seems quite interesting. It started in 2013 at Facebook, and it uses JIT to optimize its queries.
Apache Spark
This one is very popular, so worth checking out. It uses the Scala compiler. It might be hard to squeeze it into a benchmarking tool though.
Tajo
Yet another JIT powered by the JVM, but it seems abandoned and it doesn’t seem like it has much unique going on. It’s a distributed data warehouse system
Others
Mutable
Website | Code | Research paper| Benchmarking
As they say, the main goal of this database is to produce prototypes very quickly for research ideas. They remedy this with metaprogramming and just in time compilation. Turns its code into Wasm which is backed by the V8 engine
GreenPlum
Seems to be a data warehouse that uses Orca for the query optimiser
Greenplum utilizes query compilation for predicate evaluation, tuple deform and primitive type functions, etc. It doesn’t compile the execution engine into a push-based model. As it is mentioned in the Query Execution section, the execution model is volcano pull style.
Greenplum differs from Postgres in 3 ways, first it leverages Orca as a query planner
QuestDB
This one seems quite interesting. It’s a time series database though, so it might be hard to compare to the others. I think it uses a novel? JIT compiler so it could be neat
RaptorDB
Abandoned, but it seems quite interesting. It’s a key-value store for JSON documents and it uses the .NET runtime framework to optimise it’s query compilation
StarRocks
Seems quite interesting. Doesn’t specify how it does the JIT compilation on this page.
Proprietary
HyPer
ExtremeDb
- https://dbdb.io/db/extremedb
- Strictly a commercial database, so it seems sort of interesting, but it seems incredibly flexible and it ended development in 2021. Could be worth trying to read into/understand. TODO.
- Firebolt
- https://dbdb.io/db/esgyndb
- Branded as a low latency database, which seems interesting. Specifically a cloud data warehouse though so I’m not sure whether it’s particularly relevant
- TODO
HANA
- Seems somewhat interesting, but it’s a column oriented and in memory database. Apparently it uses LLVM JIT for query optimisations, which means it might not be that unique to look into when we already have LingoDB serving a similar role
PieCloudDB
- Seems everything about it is in Chinese, and supports AI models. Not sure how keep I am on this one since it has to do with OLAPs - analytical processing
Proteus
Yet another LLVM-supported database query optimizer. It has some GPU optimizations in it, but it seems to have quite a lot of publications. Most seem to be more focused on the GPU side, but some of them have information about trying to get CPU-GPU parallelism in JIT compiled engines.
Umbra
This one looks quite interesting. It has a fairly specific query compiler and ultimately feeds it into LLVM, but it also has a lowering through “Flying Start”
Irrelevant databases
- https://dbdb.io/db/aresdb
- Database by Uber that’s used for analytics and is a GPU-based database. There doesn’t seem to be much information about its JIT, and the main focus is about it being GPU based.
- https://dbdb.io/db/activepivot
- Seems to be a very specialized database for multidimensional data, and the JIT component is only for Multidimensional Expression queries. They moved over to be mostly about analytics on their websites, and it’s called something else entirely now.
- https://dbdb.io/db/blazingsql
- Seems like a semi-interesting database with GPU acceleration. It uses RAPIDS for compiling it’s code, and CUDA has support for JIT in the compiler. It seems mostly about GPU and, and “ended” developedment in 2021 according to the dbdb io page. The last commit on their github was 2 years ago, but it does have 2000 stars
- It is interesting that they’re using RAPID though, that might make it worth looking into since it’s a bit more novel and with JIT
- https://dbdb.io/db/cedardb
- I can’t really find much information on their docs about the JIT component of this database. It seems to be the commercial offering of Umbra… so we may as well look into umbra instead
- https://dbdb.io/db/datomic
- Compiles with Clojure, and this produces java byte code which is then JIT-compatible with the JVM. Moderately interesting, but it’s proprietary. Could be worth trying to benchmark and read about though. I’d rather find some database that uses the JVM for query optimisation and is open source which leads to Derby
- https://dbdb.io/db/esgyndb
- The description on dbdb seems interesting, but the hyperlinks lead to to a Chinese website which doesn’t look useful at all
- https://dbdb.io/db/juliadb
- Seems to be unmaintained and they moved to https://github.com/JuliaData/DataFrames.jl and https://github.com/JuliaParallel/DTables.jl. Not sure if either one uses JIT
- https://dbdb.io/db/splice-machine
- This one might be relevant, but it seems to be HBase, SparkSQL and Apache Derby glued together.
Papers / news about JIT in database compilers
Exploring Simple Architecture of Just-in-Time Compilation in Databases
- This is written at the same university I’m at, and with the same supervisor. So. I should read this properly
- Mentions there are two categories of JIT, Query Plan Execution (QPE) and Expression (EXP)
- HyPer is a QPE example
- PostgreSQL is a EXP example
- Notable JIT-based systems include PostgreSQL [12], HyPer [8], Umbra [14], ClickHouse [7], and Mutable [6], with HyPer being a representative pioneer.
- They say HyPer is the representative pioneer of this idea, but it’s very complicated, it’s hard to test, and it isn’t very extendable. They want to make a JIT-style system that counters these with low engineering effort, easy testing, and compatible with the ecosystem
- They end up piggy-backing off LLVM. The rest is basically what you’d expect for this architecture - compile SQL statement into C++, feed C++ into LLVM, use LLVM’s JIT compiler
- It feels like the vast majority of their effort is in SQL → C++, they write,
-
From SQL to C++. In this process, each query’s code is manually written according to the sequential flow of database operators. That is, each query undergoes a manual pass phase to generate C++ code, ensuring that the output results are consistent with the results produced by PostgreSQL
- My question is, shouldn’t PostgreSQL already have code that does this?
-
- They quote quite ambitious performance metrics that are significantly better than psql. They only go up to 1GB of data though, which I don’t think is enough. I.e. their bigger query takes 1000 milliseconds
- They quote some future work they’d be interested in.
- Converting SQL → code
- Using MLIR
- Expand the number of SQL operators
- Support better parallelisation + vectorization
- Integrate it into existing databases
- Make a query optimizer that supports JIT. Current ones support AOT
- Caching JIT code
I am curious whether this is vanilla PostgreSQL, or if it is actually JIT-enabled
An Empirical Analysis of Just-in-Time Compilation in Modern Databases
- Again, this one is also published by my university
-
LLVM serves as the primary JIT architecture, which was implemented in PostgreSQL since version 11
- This time, it seems they know about JIT in PostgreSQL. Maybe I didn’t read the last paper properly then
- Their main goal in the abstract is to compare PostgreSQL’s JIT to Mutable’s JIT
- Side note: What is WASM? We can compile a number of languages into Wasm, including LLVM IR, and the main purpose is that it’s useable by web technologies. Seems very weird to do a comparison with Wasm to me though, shouldn’t the pure LLVM destroy it?
- Sort of weird, this article groups JITs into LLVM and WASM approaches
- They also list Hyper, but spell it as Hyper, not HyPer. I assume that’s the same thing. They pick PostgreSQL as a representative of the idea instead of HyPer though
- Yeah, so I think the wasm side goes LLVM → WASM IR → Jit by V8 and binaryen
- They have nice diagrams for the JIT architecture of PostgreSQL and Mutable
- It seems Mutable’s advantage is it feeds their entire query execution plan, while PostgreSQL only does expressions
- Mutable completely destroys postgresql. Also, they have much larger databases. Postgres’s JIT doesn’t actually seem to make much of an impact on postgres itself, but then they also seem to have a graph that says the benefits first happen at large queries. They never test for 10GB queries between Mutable and PostgreSQL
- Discussions and future work
- Integrate WASM into PostgreSQL
- Expand operators into Mutable
- Harnessing novel hardware
- Expanded practical evaluation - just compare even more databases
I kind of disagree that WASM is the thing that’s making Mutable fast. I’m not sure how good WASM actually is, it’s just when I think of the best JIT around I imagine the JVM because it’s the oldest and most researched. Really the thing that’s making it fast is that it has the whole query plan, and not just the expressions. I think their other paper basically proves this, because it also uses LLVM but gets significantly better results by passing in the entire query plan.
It is sort of interesting that they use PostgreSQL as a representative of HyPer, when HyPer is actually a QPE based compiler while PostgreSQL is a EXP one. I guess I should add a TODO to categorize all the above databases into 1. Compiler used, 2. QPE or EXP. I guess if I have a set of open source databases that are {LLVM, JVM, WASM} x {QPE, EXP} then I’d be fairly happy.
Just-In-Time data structures
- Seems this one has to do with improvin indexing methods with a JIT approach.
- Currently when we make an index on something, it’s an all-or-nothing. If you add an index, it maintains the B-tree or other data structure which has an overhead cost. This might not even be an optimal tree if they’re doing only a subset of queries as well. We want a JITD, which changes depending on the current load. If there’s lots of writes, writes should be fast
- So this seems fairly different to compilers, but it is an interesting idea. It isn’t really query plan optimisation either, so I’m going to stop reading this one.
Towards Just-in-time Compilation of SQL Queries with OMR JitBuilder
- This is probably the most relevant article I’ve seen to the idea of attaching MLIR to QPE
-
The goal of our work is to generate efficient machine code for scan, filter, join and group-by operations for a given SQL expression by Just-in-time (JIT) compilation using the OMR JitBuilder compiler framework
- OMR JitBuilder sounds similar to MLIR, except it goes straight to JIT instead of needing to be put through LLVM. So less effort
- They attach this to PostgreSQL 12.5! This seems like an actually interesting article then!
- I should read into Volcano-style query executions…
- They found a functoni called
ExecInterpExprwhich is very expensive. I assume it’s “execute interpreted expression” - The key thing is that JIT in PostgreSQL compiles only expressions,
e.g.
SELECT x + 5 from table_a, does JIT onx + 5. Theirs does JIT on the actualSELECToperation - Their result is a small ish speedup, but it’s a consistent improvement. It’s between and sort of bounds
Just-in-time Compilation in Vectorized Query Execution
- This is a very long article.
- It has a nice explanation of what the volcano model is
- There’s a short list of other databases that try to do JIT, but not many - HIQUE, Hyper, JAMDB, Daytona and ParAccel. TODO: Add these to the list of databases above
- So this paper is quite extensive and impressive. However, it’s written in 2011, and it’s mostly thinking about gcc.
- They’re mostly trying to evaluate how much JIT is worth using, and unsurprisingly, arrive at the most complex solution to implement. Combining JIT with some vectorization in other places.
- Which is a bit interesting, because that might be in direct contradiction to the idea of QPEs being the new best thing since sliced bread.
- However, maybe it’s possible to attribute this to them using a C compiler instead of some LLVM style thing
- It’s a very long article, and provides a lot of context, so I will probably need even more time to read it to be honest.
Compiled Query Execution Engine using JVM
- Has a bit more background knowledge about an SQL virtual machine that interprets a dataflow tree
- Kind of interesting, does it actually spawn a sql virtual machine? what is that haha maybe a TODO here
- This looks like a very solid article with a pretty predictable path, but it is also in 2006. It’s mostly relevant and definitely good for quoting why the JVM is a good idea and very easy to use for JIT
- It has a nice example of how the > operator is completely unoptimized by storing function pointers for all the different implementations of the > operator
- This has a good quote about java being competitive with C/C++ which I could use! Sadly it’s from 2006 so it’s probably out of date by now… The azure quote might be better.
- They mention there are databases using Java, however, the generated code is not specialised for each query. This is something that makes a system simply using Java with a volcano model distinctly different from compiling the queries themselves
- A big thing for these in-memory databases is that they can use pointers instead of identifiers to do joins. That might not be possible in our case if it’s still only improving postgresql
- The idea of vector models seems sort of new in this paper
- Small explanation of how vectorising fails caching and copies. Not very good.
- Feedback Directed Program Restructuring (FDPR) is super interesting. It’s like a permanent JIT that spits out a new binary for you for C/C++
- They mention System R which is probably one of the oldest examples of generating code for each query. It’s worth mentioning as part of the history. It would be quite cool if all my examples can be in order of dates with how previous ideas affected them.
- I think an issue with this sort of paper is it is a bit subjective. They implemented almost the entire thing from scratch, which means the interpreted version could just be bad. I’d really only be impressed if they manage to beat some existing solution
- Hah, the picture of interpreted vs compiled plan is great
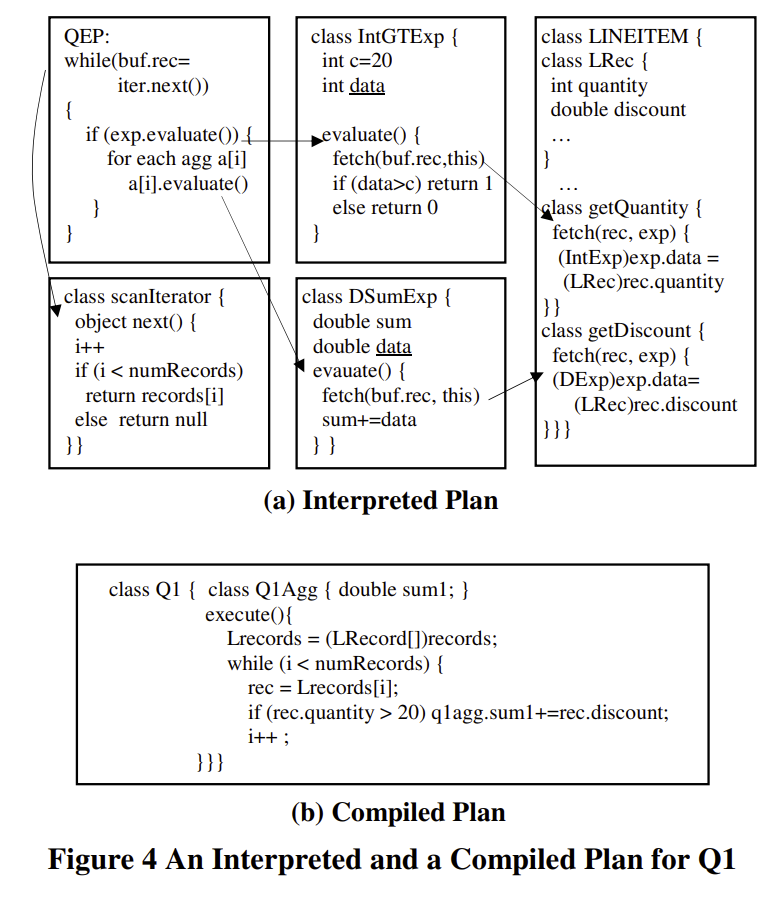
- It really shows how schizo the interpreted plans become
- haha is also a bit funny reading these old papers and they say 16GB of main memory and it’s an expensive computer
Hackerrank article on JIT in postgres
- Comments
- Overall, this comment section will be very useful for writing about what challenges we might encounter
- Comments mostly complain about the default things, but weirdly enough I think the blog post doesn’t have much to do with the JIT that was introduced inside of postgres…
- Another comment talks about uploading prepared query plans. e.g. C code or LLVM IR.
- This makes me think that if I can make my thing a postgresql extension it might be easier to convince other people to use it. I don’t NEED to get it murged into the official postgresql branch. People reply to this information that knowing what query plan you want is almost impossible with the complexity of indexing and DB data structures and ACID
- A commenter mentions that postgresql is not aware of TOAST sizes. I’m not actually sure what this is, but this comment is very good for the challenges we can encounter
- Someone mentions “MIR” as an alternative to LLVM which might be faster to compile
- There’s fear that the maximum improvement is 2x but the maximal slowdown is unbounded.
- Slides
-
These slides are REALLY good and I’m sad that I don’t see a link to a research document here…
-
In trivial queries the expressions takes the vast majority of time if it’s interpreted. These slides have a nice example of SELECT COUNT(*) FROM tbl WHERE. (x + y) > 20, and the expression is 56% of runtime but drops to 6% with LLVM
-
Their goal is CPU intensive queries as well
-
A couple of interesting looking DBs referenced here - Hyper, vitesse DB, Butterstein, and New expression interpreter. These are all very relevant for postgres so definitely worth exploring theseTODO
-
This is a nice source because they show even in TPC H queries they get substaintial speedups. Worth quoting to show that it’s a good thing to do
-
Before they compile with JIT they have a round that checks whether it’s even supported
-
I am a bit confused about which part of the query execution does this actually get done
-
It is also interesting that they recommend swapping to push-based… it seems like a bit of a side note
-
JIT compilation at different levels is an interesting slide. Since it sort of adds support for an MLIR idea. Maybe we can have some form of a dynamic compiler - it might compile expressions at level X, backend functions at Y, executor at Z
-
They boast a huge improvement for postgresql extension JIT. 5.5x. I wonder if I can find that online somewhere…
-
Cascade of doom: JIT, and how a Postgres update led to 70% failure on a critical national service
- This is definitely worth mentioning because it shows the harm JIT could do
- There isn’t much to say here other than describing it
Ignite query engine
- Before this overhaul, ignite had large holes where some queries simply cannot be run because the backend splits it into a map query then a reduce query
- Hmm I actually need to look into how postgres uses the cursor output from execution
- Hmm I don’t think this is particularly useful. It runs over how to plug Calcite into ignite, but not really much about Calcite itself. It has some implementation details about the rounds of optimisation I guess
Introduction to Apache Calcite
- Calcite is an toolkit that supports SQL parsing, validation, optimizer, generation and a data federator
- This all seems very generic. I guess this isn’t a great explainer of what ignite is actually doing… It seems oddly like a generic database query engine with nothing special. So I’m still confused why ignite seems to be #1
To read through
Annnd this redis link is dead because I’m not online. I guess I’m not logged in so. https://www.hellointerview.com/learn/system-design/deep-dives/redis