
Hello! So here’s the plan with this. I’m going to go back to T1W1 - Readings and write out notes on articles, then I’ll flick back over here and put it closer to the structure the thesis wants. After a round with this page, I’ll go write it out again in LaTeX for the actual document. That isn’t going to be a straight copy paste, and I’ll purposefully make this page less formal so that it isn’t something I can copy over easily.
Probably easiest for the marker if I just title the sections according to the format they gave me.
Preliminary
To investigate just-in-time (JIT) compilers we need to understand and define a handful of topics. In this section we will define how relational databases are typically structured, what a JIT compiler is and how it can help, what operating system details are important to know, and what multi-level intermediary representation (MLIR) is.
What is a typical database structure
Most relational databases are structured like this:
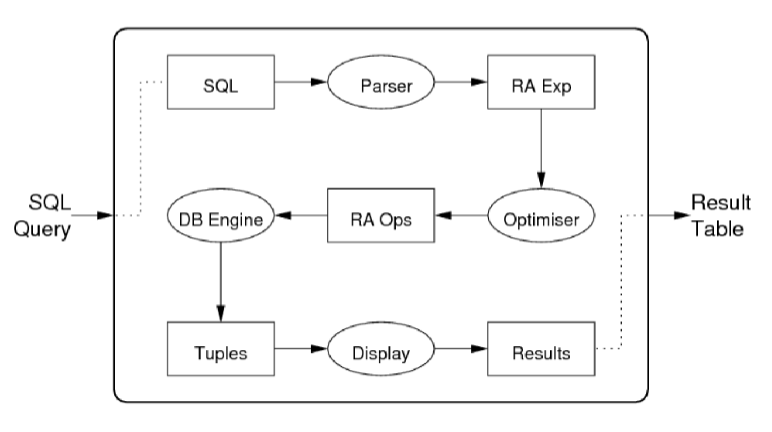
Structured query language (SQL) is parsed, then converted into a relational algebra expression, which allows us to run an optimizer, and convert this relational algebra expression into operators. This can then be executed by the database engine.
An example of this is
SELECT * FROM tbl
Which would be translated into
something
inside the expression parser, and that would become
something
inside the RA ops stage.
At that point it generates a tree of operations that are pull based. The root of the tree calls next(), which causes the child to collect information. This is done down to the leaves of the tree which typically read information from tables.
< image >
The major issue tuple-at-a-time causes in modern systems is that our caches have become larger over time. Somewhat of a workaround has been made a result, which is vectorised execution. This uses the same structure, but the next() operator produces enough to fill caches. However, doing this can cause significant other issues due to requiring more copy operators, and database operations like a join can over-fill the caches by accident. In most comparisons between the two, the gain from doing this isn’t significant enough. source
Overall, databases have evolved into this structure because the pipelined architecture supports modular development for more individuals to work on it, and simplifies the understanding of the system.
What is a JIT compiler
Modern, on-disk databases consider CPU-based operations to be O(1) time complexity because of how expensive loading in from buffers is. As a result, JIT is primarily considered in the context of in-memory databases because it mostly benefits CPU-heavy loads.
JIT compilers were made to assist interpreted languages so they can become fast while maintaining the benefits of being interpreted. An example of this is the Java compiler
< image of java compiler thing >
It depends on configuration, but by default after 10,000 iterations of a piece of code it is elected to be compiled by JIT. Advanced compilers can do this compilation process while continuing to run as per normal. The big advantage that JIT gets here is it has statistics about how often a specific branch was ran during those iterations and thus the branch prediction can be significantly more accurate. Azul quotes that JIT can become 50% more performant than ahead of time code, and this is further supported by Java being able to match or even beat C code on maximum optimization.
The main issue this introduces is that before the code is warmed with the JIT compiler, performance is poor. Inside the Java ecosystem there are also systems that support caching JIT compiled code. The main vendor of this is Azul, which is a paid service that can save your java virtual machine state. However, depending on the context, this might not be preferable because the benefit of JIT is that branch prediction calculations are personalised. So typically inside a database with separate queries, doing JIT is not always beneficial.
In the context of databases, most applications of JIT can be split into compiling only specific sections of the query (typically called EXP for expression) and others that are compile the entire query plan execution (QPE). The results of this choice will be explored in the Current State section.
Relevant Operating System features
To understand choices on database and JIT development, it’s important to cover important operating system features. There are two important OS-level operations a JIT compiler improves. The first is central processing unit (CPU) scheduling, and the second is cache management.
In the context of a multiprocessed database, a CPU can transform sequential execution into pipelined execution. Essentially CPU instructions are split into Instruction Fetch (IF), Instruction Decode (ID), Execute (EX) and Write-back (WB). The CPU can do multiple of these within a single a single cycle, however, they need to be independent. It’s effectively a topological sort problem.
The other part of this is branch predictions. Whenever there’s a conditional in code, during these instructions the CPU has the ability to guess which branch it has to go into without evaluating it, and then a different set of instructions can evaluate it later. However, when it is incorrect, it can effectively cause the CPU to need to backtrack. Since the processor set up this pipeline of instructions it can do, it can cause a significant step back and a recalculation of this pipeline. As a result, we should be able to see that the effect of branch mis-predictions is very large.
The other part is cache usage. A computer has multiple levels of memory. CPU caches typically take X nanoseconds to be accessed, and if that fails it moves to the TLB buffer. If the TLB buffer fails, it moves to the page lookup and at this point accessing RAM is approximately 100 microseconds. If it is not not the ram yet due to how on-demand paging in an OS works, it triggers a page fault which loads the data from secondary memory into the primary, and this can cost approximately 10 milliseconds.
All of this adds up to if the cache is managed effectively, it can shift the cost of fetching data from 10 milliseconds down to 1 nanosecond.
JIT enables both of these because it has data about when branch prediction is correct, as well as optimizations for how to use the cache more effectively. As a result, even if the majority of the cost is loading in data normally, our JIT compiled queries can lead to cache usage being more effective and leading to less secondary memory reads.
What is MLIR and LLVM
LLVM is a project that supports building compilers. A large portion of compilers use its toolkit to assist because it saves them the work of rewriting normal compiler optimisations.
Mutlilevel intermediary representation is a toolkit that supports making compilers. Essentially it has the usual toolkit of LLVM, but allows you to create your own dialects and lowerings before that.
< example of code generation >
The advantages of this will be explored in the Lingo DB section.
Current state
1. Brief overview of what will be covered
In the following section a series of relevant databases and their architecture will be explored. This consists of System R and Daytona, which were very early database systems but used compiled queries. Then JAMDB and HyPer will be explored as they were pioneers for the idea of utilizing JIT inside of a database query pipeline. Following that will be Umbra and HyPer’s addition of adaptive query compilation which suggested adding a pre-compile round before JIT so that there is never an interpreted stage. PostgreSQL is older than those, but it is a production-ready database that adopted EXP compiling with real world impacts so it is worth exploring. The very recent JIT-supporting databases, Umbra, Mutable, and Lingo DB will be explored after that.
2. System R
System R was the first implementation of structured query language (SQL) and was made in 1974. It’s worth noting here because it compiled the SQL statements down into machine code, rather than following the idea of an interpreter. Their core vision at this point was supporting ACID requirements specifically at a “level of performance comparable to existing lower-function database systems” (A history and evaluation of System R). They go as far as to call the choice to user a compiler “the most important decision in the design”.
A large benefit they quote of having a compilation stage is that the overhead of parsing, validity checking and access path selection are not in the running transaction. They included a pre-compiler which had join optimisations. Their compiler had pre-compiled fragments of Cobol for reused functions, and would use these to improve compile times. The compiler itself was very custom because at the time tools to support compilers were not common.
It’s a study which highlights that the idea of compiled queries is not new, and that over time database systems put less importance on having the best performance and focused instead on correctness.
3. JAMDB
In 2006, IBM’s research centre published an article about compiled query execution using the JVM for an in-memory database. In this they created two pathways for code,
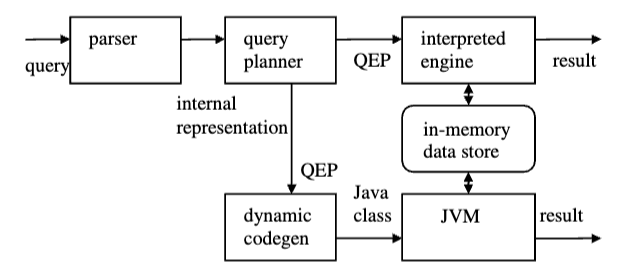
One is feeding it into an volcano interpreted engine, and the other is using dynamic code gen. An issue they encounter in this comparison is that it is difficult to implement both of these to an equal quality. There are small things in each that can be improved or omitted; the Java compiler will be a fully production-ready system that is refined, but their interpreted engine was hand-written.
They have a solid representation of how large of a difference using a interpreted plan is compared to the compiled plan in terms of compiled code. This is generated from Q1 in the TPC-H queries.
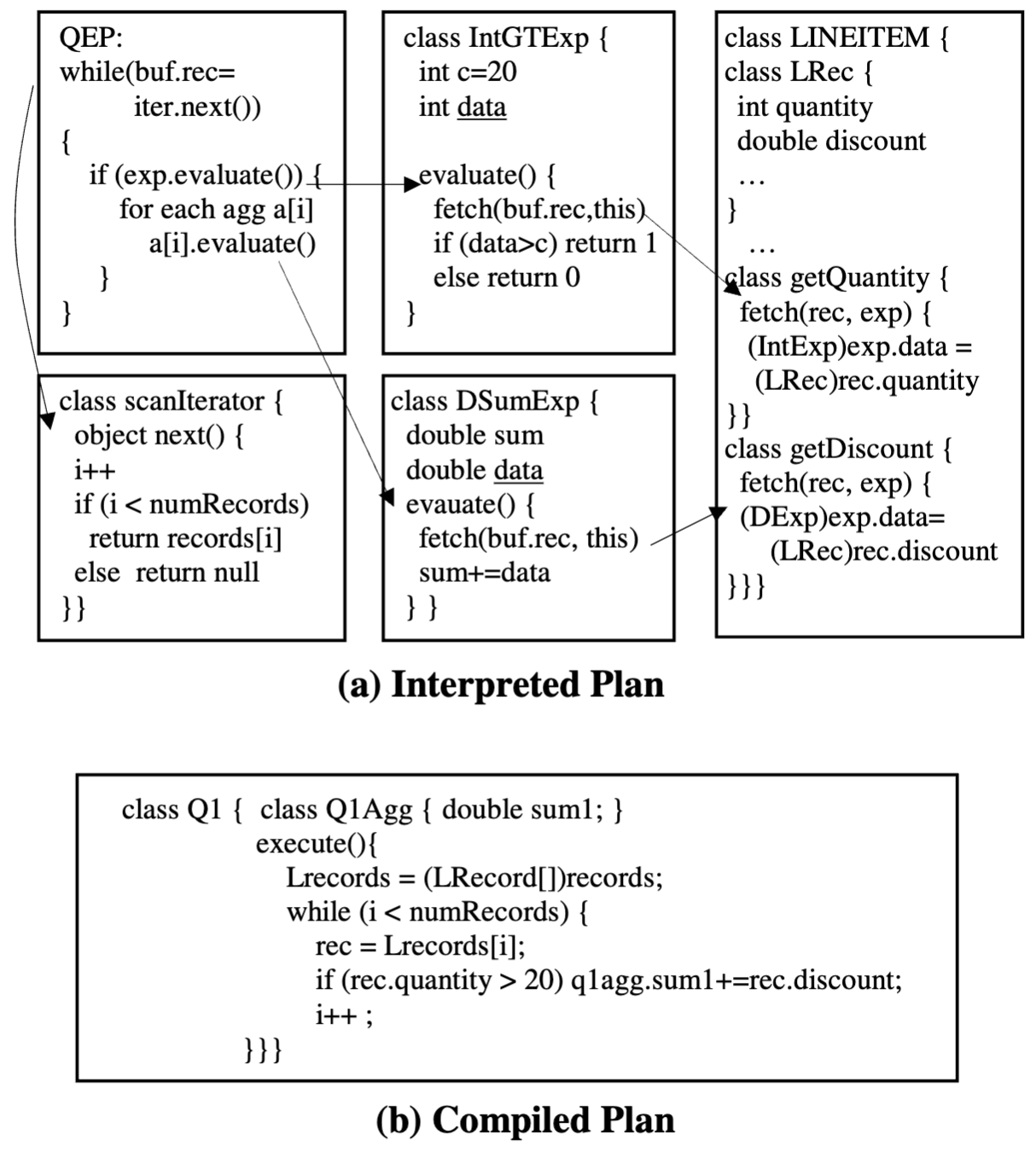
Every layer in the interpreted plan adds a function pointer overhead and would slow it down. Depending on the query, their results show between a 2-4x speedup in JIT, and that on average their interpreted plans have twice as many memory accesses on all levels of memory (primary, L3, L2). Another effect is that there are over ten times more branch prediction faults in the interpreted plan.
They finish the piece that while these results are very promising, they didn’t implement persistence, locking, logging, recovery and space management, and the core issue is that writing their compiled code is harder write and maintain. Their conclusion is they need further research to simplify writing the code in the future.
4. HyPer
HyPer is considered the pioneer of the field for JIT in databases because it is commercialised; it has enough features implemented to be used on a commercial scale, and was acquired by Tableau in 2016. The project started in 2010, with their flagship paper releasing in 2011 for the compiler. The database being commercialised does introduce issues for outside research as the only resources that can be accessed is the binary they released online as well as the papers. We are unable to see the codebase itself.
The revolutionary thing that HyPer did was that they realised translating their queries into C or C++ had a significant overhead compared to LLVM. They managed to reduce their compile time by a factor of twenty by taking on an architecture depicted below. They pre-compiled the C++ implementations of common functions and tied them together using LLVM. This LLVM code would be executed using LLVM’s JIT executor. Using LLVM allows them to produce better code than C++ because it lets them configure specific features like the overflow flags, and it is also strongly typed which prevented many bugs that was inside their original C++.
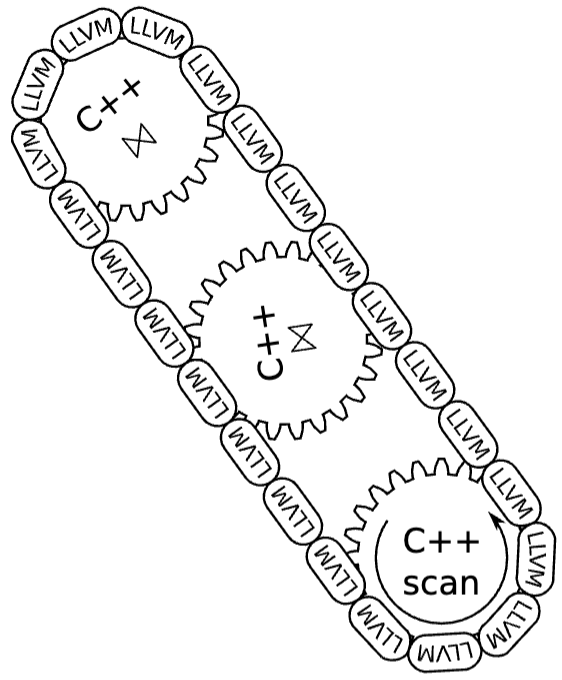
This was so effective that typically unimportant parts of the queries became the bottleneck - they comment that for Query 1 over 50% of the initial plan’s runtime was spent on hashing, even though they only hash two values.
They also compared their code to MonetDB in terms of number of branches, branch mispredictions, and cache misses. Generally speaking, the code that Hyper produced had 5-8x less branches, resulting in a similar reduction in mispredicts. This table can be summarised as HyPer simply has less code in it’s compiled queries, which results in less hazards being encountered during runtime.

While they did reduce their complexity by adding C++ modules, this is still a very large amount of complexity that does not exist in the majority of very successful database systems.
In a later paper, Adaptive Execution of Compiled Queries, HyPer improves their compile time by breaking it into stages. They can use an interpreter on LLVM IR, then for the next stage they developed an LLVM byte code interpreter, followed by the choice of running the optimiser or not. Furthermore, they point out that compiling is mostly single-threaded while modern query engines can run multi-threaded. Dedicating a single core to compiling in many cases is not a major commitment, so they added support for running the query while a separate thread optimises it when it’s necessary.
An important detail they mention is that the query cost model is often very inaccurate, and can be harmful to compilation choices. This can be very severe (the level of impact can be see in PostgreSQL) so they make the decision to shift to monitor execution progress. Inside of their execution model, they have jobs that are ran and inside their work-stealing stage they log how much time the job took. With that and the query plan they have the ability to accurately estimate the time for a job and can calculate the theoretically optimal compilation level.
< add image of how much these improvements changed the database >
The combination of adding additional stages to their LLVM compiler, supporting multithreading between compiling and execution, and more accurate cost analysis transforms their approach into a viable JIT application. It does, however, seem that they are largely building a new JIT compiler from the ground up. There isn’t much unique about the improvements here to the database itself - they are almost all choices inside the compiler.
5. Umbra
The initial paper for Umbra takes major ideas in in-memory databases and applies them to an on-disk database, reasoning that the improvements in SSDs has made doing this worthwhile. It takes ideas from LeanStore for buffer management and latches, multi-version concurrency control from HyPer, and the compilation and execution strategies from HyPer as well. All of this produced a database that is more flexible, more scalable, and still faster than HyPer. Fundamentally speaking, this shows that a database that is focused on proper buffer management can achieve the same speeds as an on memory database if it has a high quality buffer management system.
Following this, they used Umbra as a base for several research ideas. On Another Level: How to Debug Compiling Query Engines talks about debugging a compiling query engine requiring a multi-level debugger. It’s not viable to attach a debugger to the database like volcano models because the engine compiles it into a whole new program, and attaching it straight to the SQL with markers added to the intermediary representation obfuscates how operators work. To remedy this they add a time-travelling feature that replays a recording of the code generation and lets them see the context.
In another follow-up paper, their approach of making their compiler have their own JIT stages shows benefits. In Efficiently Compiling Dynamic Code for Adaptive Query Processing they introduce the idea of changing query optimisation choices in the middle of their execution time. This can be particularly useful when their cost model makes an inaccurate choice, and they quote that it can improve the runtime of data-centric code by more than 2x.
This feature is usually added either by invoking the query optimiser multiple times; either during runtime, or at the start with the ability to swap between the plans. Other systems using routing where the plan itself has the ability to swap between optimisations built into the plan itself. Since Umbra is compiled, and compiling has a high overhead cost, they opt for the second choice. The ability to do this synergises well with using a just-in-time compiler because if the query changes an optimisation choice early in, it only needs to compile the correct choice.
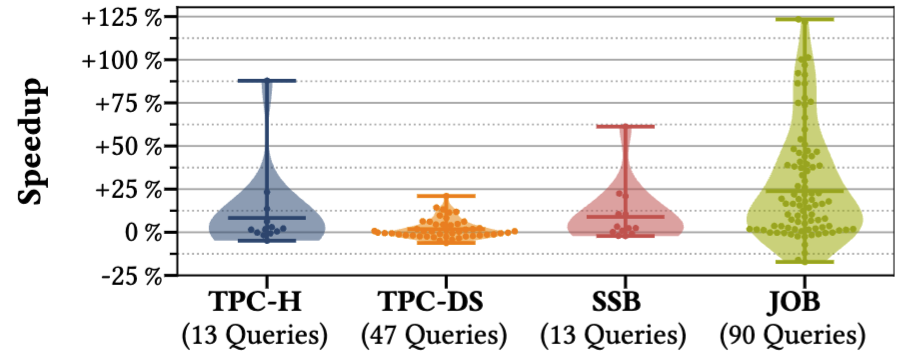
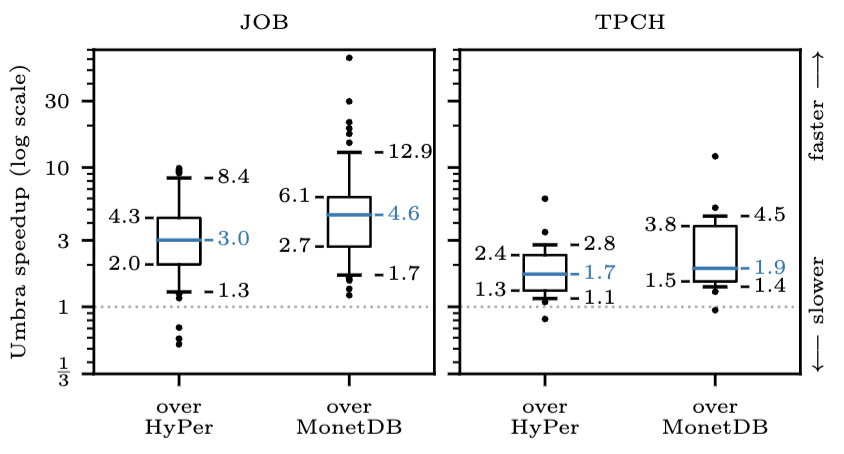
Overall, Umbra manages to place as the most effective database according to Clickhouse’s benchmarks. It’s one of the most exhaustive
TODO: I note that inside the mutable paper they table about Tidy Tuples and Flying Start. I should add these
6. PostgreSQL
- Be sure to introduce the ability for PostgreSQL to have extensions like TimescaleDB Definitely also say PostgreSQL is old, and the main motivation is just that someone was willing to do it. It wasn’t particularly heavily researched, and mostly a project that went badly.
PostgreSQL’s interaction with JIT is worth exploring because it’s the most widely used database, and the introduction of it is widely considered a net-negative that should be disabled. Due to PostgreSQL being open source, a number of features take the philosophy of if someone is willing to implement it and it’s optional, it may as well be added. As a side effect, there aren’t quite research articles explaining how it was implemented or benchmarked, and the main sources are the pull request that added it, documentation that was added with it, and news articles that released when it was released in the stable version.
JIT was added by Andres Freund in this discussion. He primarily talks about getting the benefits from JIT for CPU-heavy queries by only compiling expressions (e.g. the x > 5 in SELECT * from tbl where x > 5) and that tuple deformation benefits a lot from it. A notable response that Peter Eisentruat was that the default jit_above cost was too low.
 This feature was added in PostgreSQL 11, but it was disabled by default. The authors agreed that this meanttodo (find source) the feature would largely be untested, and enabled it by default in version 12. This had negative real-world impacts, for instance, the UK coronavirus dashboard collapsed with a 70% failure rate on queries. This translated into user experiences being widely negative, and since it’s been a few years since the event, it would be hard to convince people to shift to a new implementation even if this is fixed. Large-scale issues like this are why customers don’t upgrade their databases unless they encounter an issue.
This feature was added in PostgreSQL 11, but it was disabled by default. The authors agreed that this meanttodo (find source) the feature would largely be untested, and enabled it by default in version 12. This had negative real-world impacts, for instance, the UK coronavirus dashboard collapsed with a 70% failure rate on queries. This translated into user experiences being widely negative, and since it’s been a few years since the event, it would be hard to convince people to shift to a new implementation even if this is fixed. Large-scale issues like this are why customers don’t upgrade their databases unless they encounter an issue.
There have been conferences that explore pushing query execution plan JIT, like this which do look promising, but fundamentally PostgreSQL is about pushing code into the open-source repository and using it in production.
It is also possible to change this to a different compiler without a large amount of work. For instance, this has been replaced JitBuilder framework by Eclipse OMR in 2021 before. This paper had reasonable results with saving 1.5-13% depending on the query. Their examples were on quite large scale factors (4, 8, 16) and they only compared to interpreted execution but not PostgreSQL’s recently added
7. Mutable
Mutable is a recent database, created in 2023, which is made for rapid prototyping. The team reflected on the development of HyPe,r noting that they are effectively fixing problems that should belong to the JIT compiler, not the database. So they choose the V8 compiler written by Google, showing it already has support for the ability to handle similar mechanisms that HyPer and Umbra manually added.
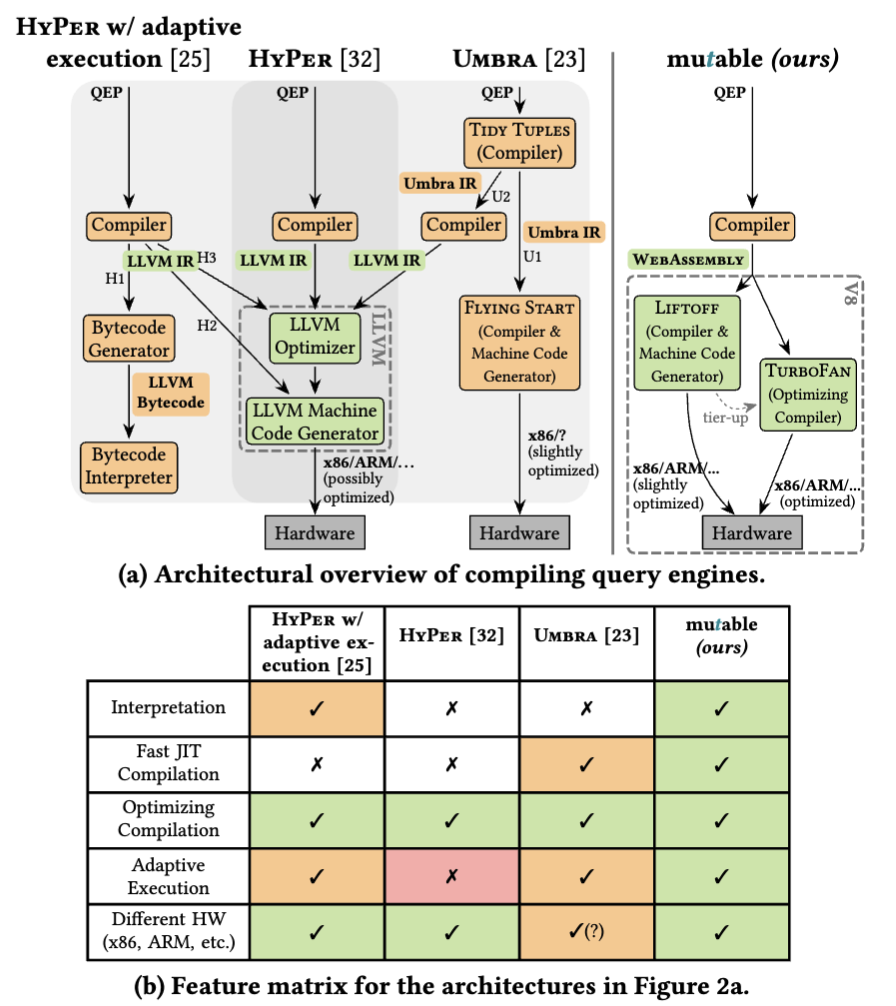
Using this, they make a query execution plan-based engine. A side effect worth noting is they do not have a deeply developed query optimiser and try to rely on the V8 engine. Their pipeline consists of turning the SQL query into webassembly as the intermediate representation and feeding that into V8.
The reason this works well is because V8 prioritizes compiling at a low latency with a small number of runs on the compiled code. Most other JIT systems are built on the idea that it should be chunks of code that are ran very frequently. V8 has a two stage compiler, the first stage is “Liftoff” which focuses on pushing functions through a code generator quickly, and the second stage Turbofan builds a graph construction with more advanced stages like optimisations, scheduling, and selecting instructions. source ( Clemens Hammacher. 2018. Liftoff: a new baseline compiler for WebAssembly in V8. V8 JavaScript engine (2018).)
Their team spent a substantial amount of Clemens Hammacher. 2018. Liftoff: a new baseline compiler for WebAssembly in V8. V8 JavaScript engine (2018). time on benchmarking, and their results show that they manage to get similar execution times compared to HyPer, and in many cases beat them. Their compilation times are significantly better, while execution is a lot better.
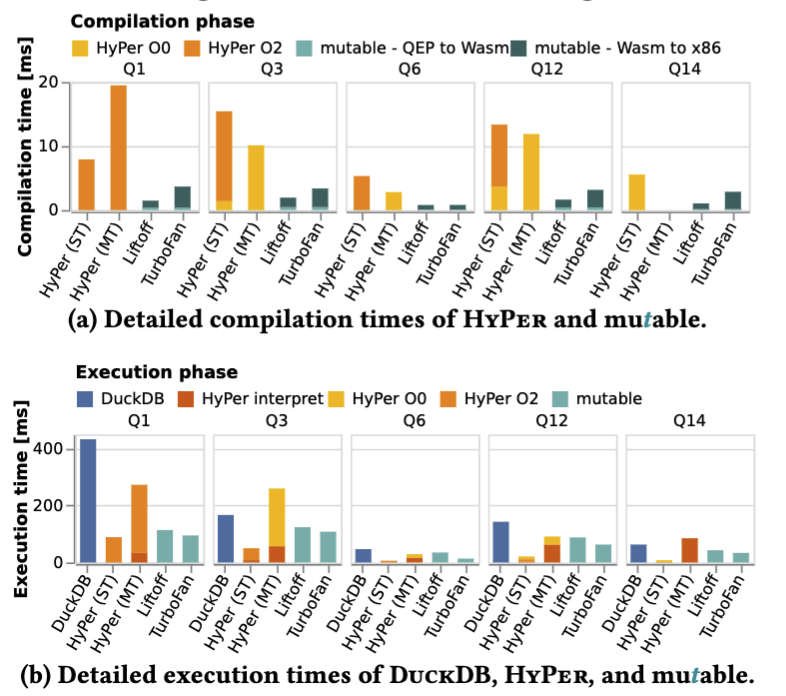
The downsides of this approach with V8 is if they want to optimise this further in the ways that HyPer did with query re-planning they might require rearchitecting. HyPer did as well though by labelling chunks of their compiled code into blocks with choices.
8. Lingo DB
Lingo-DB has a fresh approach on making a database by shifting the query optimiser into the compiler by leveraging MLIR. This minimises how much translation they need to do between layers. Traditionally, developers need to parse the SQL into relational algebra operators, then optimise on those, and parse that back into their compiled language or execution plan. Since these shifts can be supported directly by the compiler itself, it means ensuring these translations are performant is less of a concern and that there is less manual implementation.
They parse the SQL into a relational algebra dialect, and they perform five query optimisation techniques on that. So not a mature set of optimisations, but enough to show how they can be applied. Following that, they lower the declarative relational algebra into a combination of imperative dialects, which they can then lower to database-specific types and operations. Typically this is the format that database engines execute on, but MLIR goes on to inject data structures and algorithms in a lowering, and then utility types and operations in another. These are functions that are missing in standard libraries in MLIR and need adding manually. As a result, their engine mostly looks like a standard database but with steps built directly into the compiler.

The outcome is that they are less performant than HyPer, but better than DuckDB - placing them at a useable, but not optimal database. This is impactful because Lingo DB is implemented with 4x less code than DuckDB and 3x less than NosePage. Unlike HyPer, they don’t need to interact directly with LLVM IR, while also granting an easier way to add query optimisations than Mutable. There are even examples of people producing WebAssembly from MLIR, which would be able to feed into a V8 engine, such as mlir playground, but whether it’s worth the lowering time is up for the debate.
Their main suggestions for how to improve LingoDB consist of adding support for parallelising workloads and adding a dialect for distributed systems. In a later paper, they add lowerings for sub-operators which adds support for non-relational workloads. Sub-operators consist of logical functions such as hashing, filtering, or user-added functions. Adding this is unrelated to this literature review of JIT in databases, but it does show that their framework is extendable.
Gaps in the literature
A large part of the encountered literature suffered from being strictly a research database. Outside of some applications of this, the systems do not have guarantees for ACID compliance and many are only single-threaded. This aligns closely with Michael Stonebraker’s fear that database research has largely been abandoned by the customer. There is potential for major improvements in performance here, but is the risk of lacking ACID-compliance worth it to many clients? Many developers, when met with performance issues in databases, opt for using caches or hand-written code to get around the issues.
In the same vein, any additions to existing databases need to have reasonable defaults out of the box. PostgreSQL adding JIT to their database, but then the defaults being too low and enabled by default is an example of this.
Many of the above systems target in-memory usages due to them being the scenario where improving CPU-heavy operations is beneficial. However, in the JitBuilder paper they highlight that even PostgreSQL can spend over 50% of its time in the CPU, and Umbra reasons that with the improvements in SSDs JIT has become more viable.
Another problem is that writing a compiled query engine is difficult. This is one of the main reasons developers opt for vectorised executions. There are not many debugging tools compared to stepping through the interpreted code, and if it’s a compiler with multiple stages it’s especially challenging.
Swapping between compilers has been reasonably explored, but there are not many systems that explore MLIR. The problem with the way that LingoDB uses MLIR is that they propose rearchitecting the entire database to be around MLIR. Creating a new general database system, when existing solutions are so large, is not practical without substantial investment.
Problem statement
This project will aim to target integration MLIR with PostgreSQL on a query expression . This can provide a framework for adding additional lowerings, and is a substantial amount of implementation work. This would replace the interpreter entirely with an executable version.
Aims and Outcomes
The main goal would be correctness - that it matches the expected output of TPC-H queries. Following that is the performance should match the current state of PostgreSQL in those benchmarks, and that the frontend of PostgreSQL should remain unchanged. Furthermore, it should simpler than the existing execution engine and show that
Covering all of the gaps in this would be too much. Namingly, ACID-compliance, multithreading, and adding a debugger with other developer tools would be too much.